
File this under useful research:
With the growing number of rigorous impact evaluations worldwide, the question of how best to apply this evidence to policymaking processes has arguably become the main challenge for evidence-based policymaking. How can policymakers predict whether a policy will have the same impact in their context as it did elsewhere, and how should this influence the design and implementation of policy? This paper introduces a simple and flexible framework to address these questions of external validity and policy adaptation. I show that failures of external validity arise from an interaction between a policy’s theory of change and a dimension of the context in which it is being implemented, and develop a method of “mechanism mapping” that maps a policy’s theory of change against salient contextual assumptions to identify external validity problems and suggest appropriate policy adaptations. In deciding whether and how to adapt a policy in a new context, I show there is a fundamental informational trade-o↵ between the strength and relevance of evidence on the policy from other contexts and the policymaker’s knowledge of the local context. This trade-o↵ can guide policymakers’ judgments about whether policies should be copied exactly from elsewhere, adapted, or invented anew.
That’s the abstract from a new Oxford Working Paper by Martin J. Williams. It’s situated firmly within a methodological debate about scaling and transplanting policy on the basis of RCT evaluations, but is notable for it’s clarity and utility, and directly relevant to discussions about scaling and adapting civic tech programs.
The working paper is a fascinating contribution to ongoing discussions about methods for ensuring the external validity of quantitative policy analysis (see my take on why this matters for civic tech here). It’s worth reading from within that context, and for thinking about how it compares methods to strengthen external validity by increasing scope or incorporating structural modelling.
But the white paper’s approach is most exciting for its deliberate effort to facilitate “a quick and informal desk exercise undertaken by a single policymaker (2). This is where it becomes relevant for civic tech programing, and ongoing conversations about when and how to scale successful programs, and when and how to apply them in new contexts.
I won’t rehash those discussions, here, but will give a quick description of the method, which involves three basic steps.
- Describe a linear Theory of Change (ToC) for the policy/program that has been evaluated. This requires some technical knowledge (both on the project and the evaluation). Forcing linearity on what might be complex and multi-dimensional ToC’s can be painful and feel arbitrary, but is important for identifying assumptions. (linear)
- Identify most important contextual assumptions at each stage in the linear theory of change.
- Identify the most important assumptions along the ToC, and for each, identify the contextual differences between the context in which a policy/program was evaluated, and in which it is being considered for adaptation.
That’s it. Easy peasy. It’s no magic bullet of course, but there’s a few really nice things about this approach.
- It builds on a widely accepted conceptual framework. You kind of have to know how to talk about ToCs in order to get civic tech funding. So if you’re developing a program, you likely know how to draw one. That makes this accessible
- This is a tool that scales. As mentioned in the paper, you can use statistical methods for comparing data across countries, or do this for thirty minutes on a notepad. What you get out of it will likely be proportional to what you put into it, but even at the bare minimum level of input, it will produce insights.
- The model uses simple, visual tools. The above two points mean that the tools for comparing contexts can be drawn on the back of napkins. Literally. They’re also simple representations of complex thinking that can be easily and productively systematized, sometimes in surprising ways. Consider this diagram distinguishing between scaling and adapting policy. This makes clear a number of assumptions about what the differences are in contexts and how to identify the factors that are most important for considering validity. It’s not rocket science, it’s just clean.
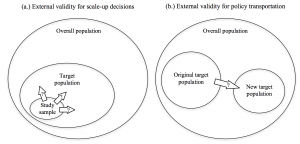
This model is commonsense in many regards. It’s probably something that a lot of us are doing informally when we think about what to try, what to fund, or what to promote for civic tech and accountability across different country contexts. And though it inevitably relies on the judgements and predispositions of the people using the too, what doesn’t?
Systematizing this approach can help promote and reinforce good practice in adapting and scaling projects. Somebody should really build this model into a short guide for civic tech project developers, and test it to make sure it’s useful. We’ve got more than enough stories of innovation. This might be a useful tool for how to build on those.



